Building a Universal Data Agent Quickly with LlamaIndex and Gravitino
Written on
In today's rapidly evolving landscape of data and generative intelligence, teams responsible for data infrastructure face challenges in making company data accessible in a streamlined, efficient, and regulation-compliant manner. This need is particularly pressing for the development of Large Language Models (LLMs) and Agentic Retrieval-Augmented Generation (RAG) systems, which have significantly impacted the analytics domain. This article will guide you through creating a data agent from the ground up, utilizing an open-source data catalog for interaction.
What is an LLM Agent?
To begin, it's essential to understand the function of Agents within RAG Pipelines. While LLMs can generate and comprehend language, they lack advanced reasoning skills. Agents enhance this capability by interpreting instructions to execute complex, domain-specific reasoning, which is then relayed back to the LLM.
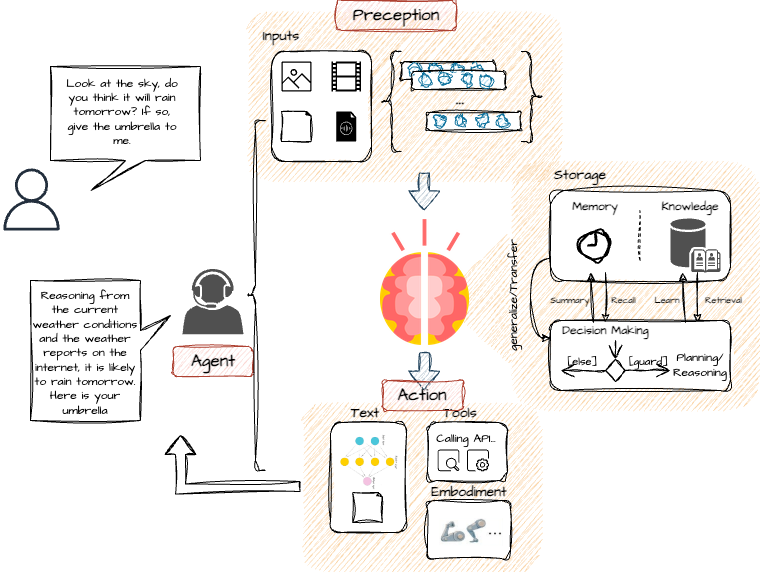
Agents can serve various purposes across different fields, such as solving mathematical problems, facilitating retrieval-augmented conversations, and acting as personal assistants. A data agent is generally aimed at achieving an extractive objective by directly interacting with the data, which can greatly enhance overall application performance and response accuracy.
Below is a typical architecture of a data agent.
The agent receives instructions from the LLM and, depending on its design, can interface with the user or the LLM via APIs or other agents. It decomposes larger tasks into smaller, manageable ones through planning, incorporating reflection and refinement capabilities. With the aid of memory, the agent can retain and retrieve information over extended contexts using vector storage and retrieval techniques. Furthermore, agents can access external APIs to gather information from various data sources, a feature that is especially beneficial.
Production Issues in RAG Development
Numerous demonstrations, proofs of concept, and tutorials exist detailing the construction of simple data agents; however, production deployment introduces its own set of challenges.
Data Quality and Integrity The precision of responses is directly influenced by the quality and integrity of the data, regardless of the LLM employed. The effectiveness of generated SQL statements hinges on the quality of metadata associated with structured data, which can lead to undesirable outcomes if compromised. Poor source data can adversely affect vector embeddings, leading to nonsensical or erroneous retrieval results. The adage "garbage in, garbage out" is particularly relevant in the context of generative AI.
Retrieving Information from Diverse Sources Organizations typically ingest data from a myriad of sources, encompassing various formats and storage solutions. Data may need to migrate across data centers and regions, complicating retrieval efforts. Failing to efficiently connect to a broad range of data sources can result in significant disadvantages, as critical data and relationships may be overlooked. The traditional ETL approach to centralizing data can also hinder response accuracy, often requiring additional time for data preparation.
Data Privacy, Security, and Compliance Ensuring data privacy, security, and compliance is crucial when developing production-level data systems, including data agents and APIs. This task becomes more complex when LLMs are involved due to their high dimensionality and complexity, making it challenging to trace outputs back to their origins. Troubleshooting such systems, especially with multiple external tool and API calls, is inherently difficult while maintaining privacy and security. It's essential to design data infrastructures with continuous visibility, observability, measurability, and robustness.
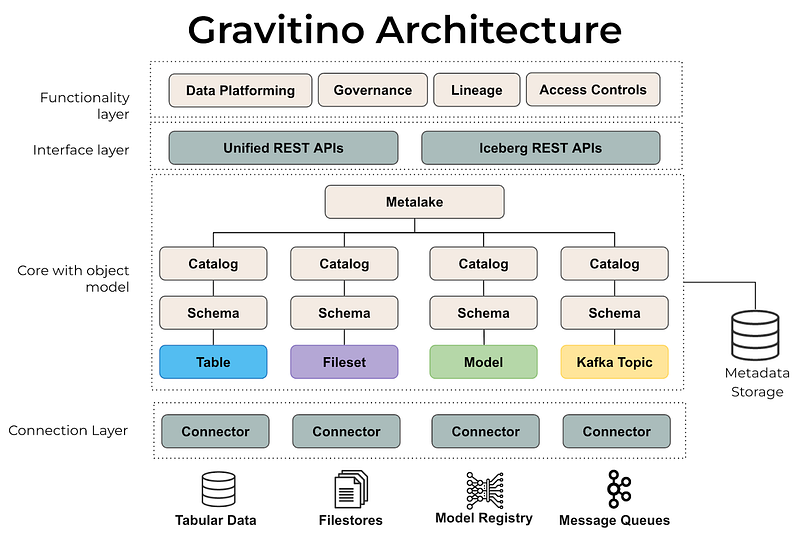
What is Apache Gravitino (incubating)?
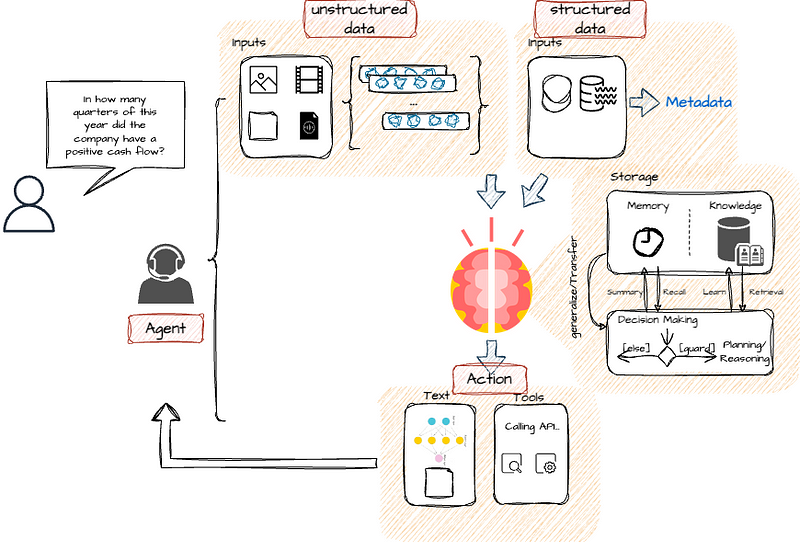
Apache Gravitino (incubating) is a high-performance, geo-distributed, and federated metadata lake. With a technical data catalog and metadata lake, users can manage access and implement data governance across various data sources (including file stores, relational databases, and event streams) while utilizing multiple engines such as Spark, Trino, or Flink across different formats and cloud providers. This integration is invaluable for quickly deploying LlamaIndex across multiple data sources.
With Gravitino, users can achieve:
- A Single Source of Truth for multi-regional data with geo-distributed architecture support.
- Unified management of Data and AI assets for both users and engines.
- Centralized security for various sources.
- Integrated data management and access management.
- An AI-ready and cost-efficient metadata fabric that standardizes across all data stores.
For further details on Gravitino, please refer to our blog post on Gravitino — the unified metadata lake.
Without Gravitino, a standard agentic RAG system would appear as follows:
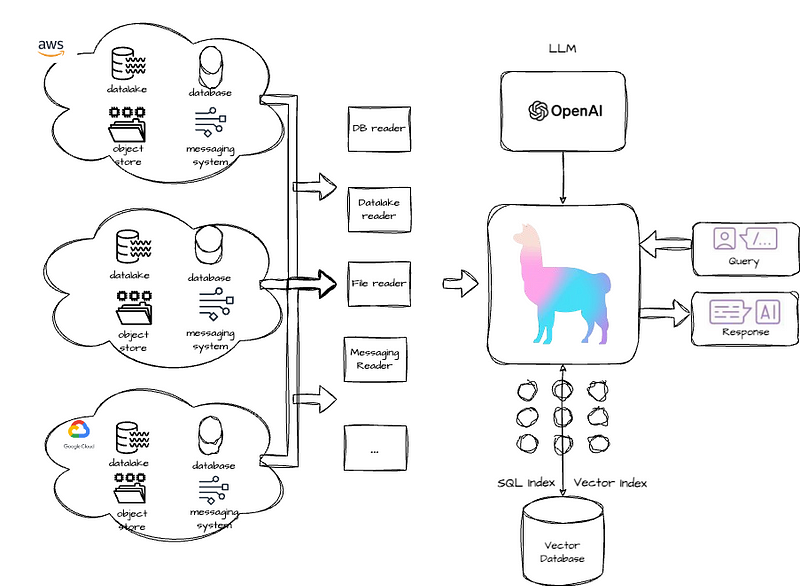
Users would need to utilize different readers to connect to various sources individually, a process that becomes increasingly complex when data is distributed across clouds with differing security protocols.
With Gravitino, the new architecture is streamlined:
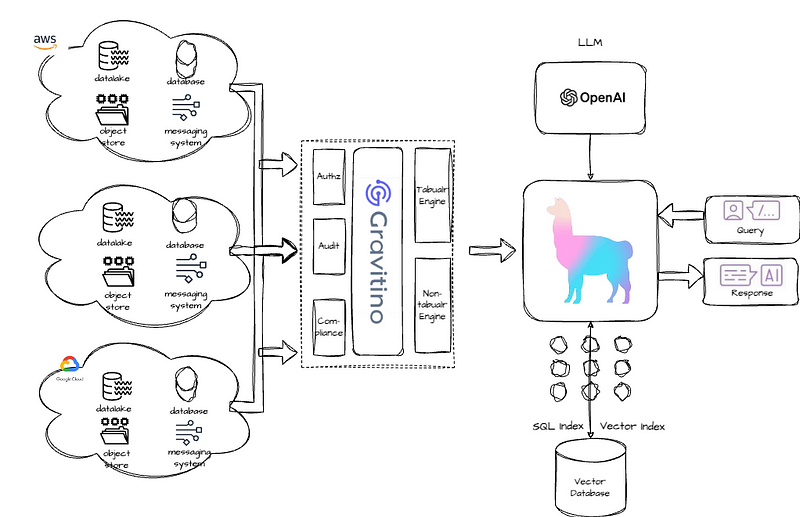
Using Gravitino and LlamaIndex to Build a Universal Data Agent
Let's delve into how to construct a data agent in just 15 minutes, which will offer several benefits:
- No data movement: The data remains in its original location, eliminating the need for preprocessing or aggregation.
- Capability to retrieve answers from both structured and unstructured data.
- A natural language interface that converts user queries into subqueries and generates SQL as needed.
Environment Setup
Below, we outline the code necessary to replicate this setup. If you wish to follow along step by step, a local setup is available. Note that an OpenAI API key is required to run this demo.
To explore the playground further, see: Apache Gravitino Demo Playground
git clone [email protected]:apache/gravitino-playground.git
cd gravitino-playground
./launch-playground.sh
Next, navigate to the Jupyter Notebook with these steps:
- Open the Jupyter Notebook in your browser at http://localhost:8888
- Open the gravitino_llamaIndex_demo.ipynb notebook
- Start the notebook and execute the cells
The overall architecture of the demo included in the local playground is illustrated below:
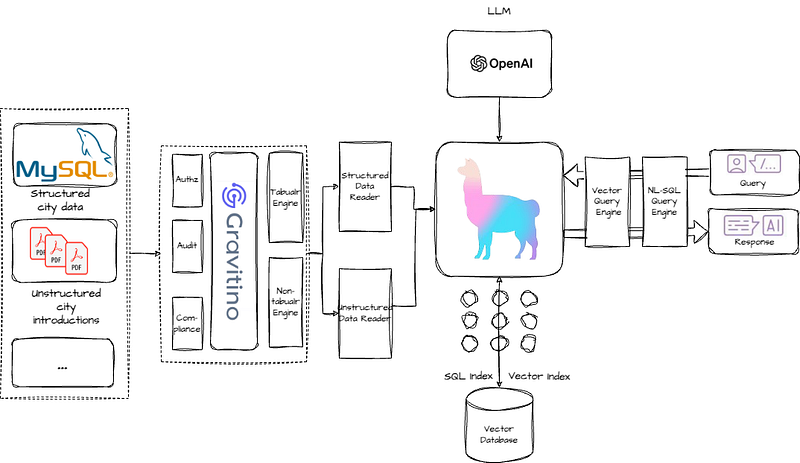
Managing Datasets Using Gravitino
First, we will establish our initial catalog and link it to our file sets, with Hadoop serving as the data source. Next, we define the schemas and specify the storage locations.
demo_catalog = None
try:
demo_catalog = gravitino_client.load_catalog(name=catalog_name)except Exception as e:
demo_catalog = gravitino_client.create_catalog(name=catalog_name,
catalog_type=Catalog.Type.FILESET,
comment="demo",
provider="hadoop",
properties={})
# Create schema and file set
schema_countries = None
try:
schema_countries = demo_catalog.as_schemas().load_schema(ident=schema_ident)except Exception as e:
schema_countries = demo_catalog.as_schemas().create_schema(ident=schema_ident,
comment="countries",
properties={})
fileset_cities = None
try:
fileset_cities = demo_catalog.as_fileset_catalog().load_fileset(ident=fileset_ident)except Exception as e:
fileset_cities = demo_catalog.as_fileset_catalog().create_fileset(ident=fileset_ident,
fileset_type=Fileset.Type.EXTERNAL,
comment="cities",
storage_location="/tmp/gravitino/data/pdfs",
properties={})
Building a Gravitino Structured Data Reader
Once our data sources are connected, we will need a method to query it. For this purpose, we will use Trino, which is linked via SQLAlchemy. Alternatively, PySpark may be utilized if that aligns with your team's existing tools.
from sqlalchemy import create_engine
from trino.sqlalchemy import URL
from sqlalchemy.sql.expression import select, text
trino_engine = create_engine('trino://admin@trino:8080/catalog_mysql/demo_llamaindex')
connection = trino_engine.connect()
with trino_engine.connect() as connection:
cursor = connection.exec_driver_sql("SELECT * FROM catalog_mysql.demo_llamaindex.city_stats")
print(cursor.fetchall())
Building a Gravitino Unstructured Data Reader
With our foundational data infrastructure established, we can now directly read it into LlamaIndex. Gravitino utilizes a virtual file system to present the data as a directory for LlamaIndex to utilize.
from llama_index.core import SimpleDirectoryReader
from gravitino import gvfs
fs = gvfs.GravitinoVirtualFileSystem(
server_uri=gravitino_url,
metalake_name=metalake_name
)
fileset_virtual_location = "fileset/catalog_fileset/countries/cities"
reader = SimpleDirectoryReader(
input_dir=fileset_virtual_location,
fs=fs,
recursive=True
)
wiki_docs = reader.load_data()
Building SQL Metadata Index from the Structured Data Connection
Once constructed, we can initiate the creation of our index and vector stores using the metadata alone.
from llama_index.core import SQLDatabase
sql_database = SQLDatabase(trino_engine, include_tables=["city_stats"])
Building Vector Index from Unstructured Data
from llama_index.core import VectorStoreIndex
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
# Insert documents into the vector index
# Each document carries metadata of the city
vector_indices = {}
vector_query_engines = {}
for city, wiki_doc in zip(cities, wiki_docs):
vector_index = VectorStoreIndex.from_documents([wiki_doc])
query_engine = vector_index.as_query_engine(
similarity_top_k=2, llm=OpenAI(model="gpt-3.5-turbo"))
vector_indices[city] = vector_index
vector_query_engines[city] = query_engine
Defining Query Engines and Asking Questions
To transform this into a fully operational chat application, a text-to-SQL interface must be developed. We will leverage LlamaIndex’s built-in functions to interact directly with the index we established earlier.
from llama_index.core.query_engine import NLSQLTableQueryEngine
from llama_index.core.query_engine import SQLJoinQueryEngine
# Define the NL to SQL engine
sql_query_engine = NLSQLTableQueryEngine(
sql_database=sql_database,
tables=["city_stats"],
)
# Define the vector query engines for each city
from llama_index.core.tools import QueryEngineTool
from llama_index.core.tools import ToolMetadata
from llama_index.core.query_engine import SubQuestionQueryEngine
query_engine_tools = []
for city in cities:
query_engine = vector_query_engines[city]
query_engine_tool = QueryEngineTool(
query_engine=query_engine,
metadata=ToolMetadata(
name=city, description=f"Provides information about {city}"),
)
query_engine_tools.append(query_engine_tool)
s_engine = SubQuestionQueryEngine.from_defaults(
query_engine_tools=query_engine_tools, llm=OpenAI(model="gpt-3.5-turbo"))
# Convert engines to tools and combine them
sql_tool = QueryEngineTool.from_defaults(
query_engine=sql_query_engine,
description=(
"Useful for translating a natural language query into a SQL query over"
" a table containing: city_stats, encompassing the population/country of"
" each city"
),
)
s_engine_tool = QueryEngineTool.from_defaults(
query_engine=s_engine,
description=(
f"Useful for answering semantic questions about different cities"),
)
query_engine = SQLJoinQueryEngine(
sql_tool, s_engine_tool, llm=OpenAI(model="gpt-4"))
# Issue query
response = query_engine.query(
"Tell me about the arts and culture of the city with the highest"
" population"
)
The final answer merges responses from two components: The first is derived from the SQL engine, which generates the SQL statement “SELECT city_name, population, country FROM city_stats ORDER BY population DESC LIMIT 1” based on natural language input, revealing that Tokyo has the highest population.
Subsequently, based on this answer, the data agent formulates three follow-up questions: “Can you provide more details about the museums, theaters, and performance venues in Tokyo?” concerning Tokyo's arts and culture.
The final response integrates these elements:
Final response: The city with the highest population is Tokyo, Japan. Tokyo is renowned for its vibrant arts and culture scene, showcasing a blend of traditional and modern influences. Visitors and residents alike can experience a wide array of cultural offerings, ranging from ancient temples and traditional tea ceremonies to cutting-edge technology and contemporary art galleries. The city is also home to numerous museums, theaters, and performance spaces that highlight Japan's rich history and creativity. Unfortunately, based on the context information provided, I cannot supply further details regarding the museums, theaters, and performance venues in Tokyo.
So What’s Next?
This demonstration illustrates the utilization of Gravitino for data ingestion and LlamaIndex for effective data retrieval. With Gravitino’s production-ready features, users can effortlessly construct a universal data agent. We are continuously enhancing Gravitino to ensure it meets the standards necessary for enterprise-grade data agents.
Are you ready to elevate your data agent? Explore the guides and join our ASF Community Slack Channel for support.
A special thanks to co-author Jerry Shao for his collaboration on this piece.