Harnessing DagsHub for Effective Data Science Management
Written on
Introduction to the DagsHub Platform
In the realm of data science, the lifecycle includes various stages: data collection, analysis, deployment, and monitoring. However, the critical infrastructure that supports this entire process is often overlooked. As data projects grow, the complexity increases due to continuous data collection, annotation, and model adjustments. Thus, maintaining machine learning reproducibility becomes challenging as different team members work on parallel versions of the project.
This article will explore how DagsHub can assist in managing data science projects effectively.
Understanding MLOps
The construction of machine learning models is rarely a singular task; instead, it involves ongoing refinement as more data is gathered and processed. Manual model creation becomes impractical over time, hence the need for Machine Learning Operations (MLOps). MLOps encompasses a collection of practices and tools designed to manage the complete lifecycle of machine learning models, including data preparation, feature engineering, model training, deployment, and monitoring.
By automating various traditionally manual tasks, MLOps aims to reduce the time and effort involved in managing machine learning models while enhancing their quality through a more consistent and repeatable process.
What is DagsHub?
DagsHub emerges as a specialized platform that fosters collaboration in data science by enabling teams to share, review, and reuse their work. Essentially, it functions like GitHub but is tailored specifically for data science and machine learning. DagsHub facilitates versioning for data, models, experiments, and code, allowing users to revert to earlier versions when necessary.
The platform integrates popular open-source tools and formats familiar to data scientists, lowering the barrier for adoption in managing data science initiatives. Key features include:
- Integration with Git servers like GitHub, Gitlab, and Bitbucket
- Google Colab for executing Python code in a browser
- DVC for tracking machine learning models and large datasets
- MLflow for monitoring machine learning experiments
- Jenkins for automating machine learning tasks
- Label Studio for annotating diverse data types (images, audio, text, etc.)
- External storage solutions such as AWS and Google Cloud Platform
- Webhooks for updating repository events through Slack and Discord
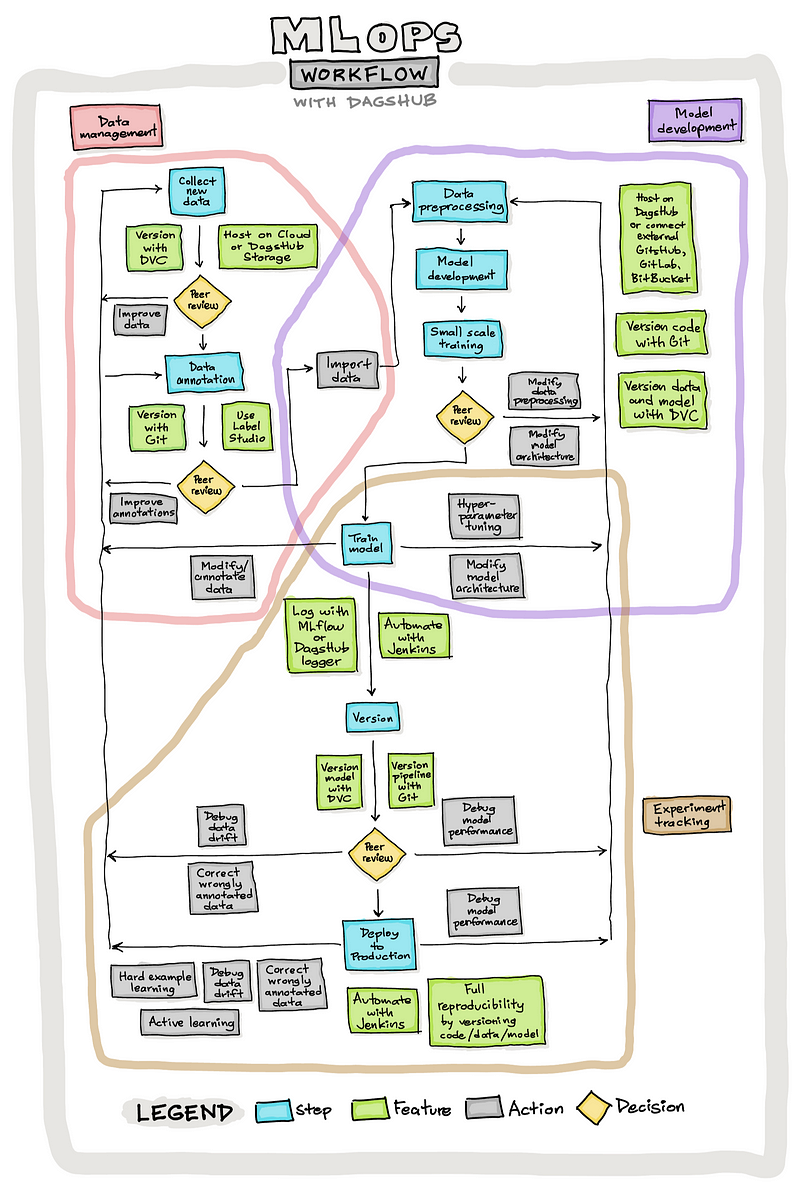
MLOps Workflow with DagsHub
Let’s examine the typical MLOps workflow for managing machine learning models and data using the DagsHub platform. We can categorize the MLOps workflow into three main components:
- Data Management
- Model Development
- Experiment Tracking
Data Management
Data is fundamental to the data lifecycle, and meticulous management is crucial for generating accurate predictions and insights. This includes data collection, preparation, annotation, and peer review. As datasets grow larger, cloud storage solutions become essential, with DagsHub offering up to 10 GB of free space in its community tier.
DagsHub allows users to easily navigate between versions, with the ability to view and compare changes directly on the platform across various data types.
Model Development
Once data is prepared and labeled, the next step is model development. This process involves applying learning algorithms to train machine learning models on historical data. Model training is inherently iterative, often requiring multiple adjustments to data processing and model architecture.
As models are developed, peer reviews can enhance their robustness, while versioning with Git for code and DVC for data ensures reproducibility.
Experiment Tracking
Tracking all components of a data project—such as data, code, and models—facilitates reproducibility and efficient collaboration within teams. Tools like DVC and MLflow help in versioning experiments, while automation via Jenkins streamlines the process. Peer reviews help verify the readiness of experiments for production.
Bringing It All Together
The MLOps workflow orchestrates three interconnected elements: data management, model development, and experiment tracking. As data is collected and processed, it feeds into model development, with all components tracked for reproducibility. This comprehensive approach allows team members to work on different aspects simultaneously, enhancing collaboration and project efficiency.
Complementary Tutorial Video
To further enhance your understanding, I've created a 28-minute tutorial demonstrating how to utilize DagsHub for machine learning projects. This step-by-step guide will walk you through practical applications of the platform.
Conclusion
MLOps is an emerging field gaining traction as more organizations integrate machine learning into their operations. This article has explored how DagsHub can be leveraged to establish an MLOps pipeline for data projects. Notable benefits include improved reproducibility, simultaneous collaboration among team members, and the ability to archive different versions of data, models, and code.
Next Steps
- How to Master Python for Data Science
- Essential Python Skills for Data Science
- A Guide to Building an AutoML App in Python
- Effective Strategies for Learning Data Science
- Create a Simple Portfolio Website for Free in Under 10 Minutes
Stay updated on my latest insights in data science by subscribing to my mailing list!
About the Author
I am currently a Developer Advocate at Streamlit and previously served as an Associate Professor of Bioinformatics in Thailand. In my spare time, I create educational content on YouTube as the Data Professor, sharing tutorials and Jupyter notebooks on GitHub.
Connect with Me
- YouTube: http://youtube.com/dataprofessor/
- Website: http://dataprofessor.org/
- Facebook: http://facebook.com/dataprofessor/