Innovative Foundation Model for Time Series Forecasting
Written on
TimeGPT: The Groundbreaking Foundation Model for Time Series Forecasting
An Insight into TimeGPT
The domain of time series forecasting is currently experiencing a wave of innovation. In recent years, significant advancements have emerged, including models like N-BEATS, N-HiTS, PatchTST, and TimesNet.
Simultaneously, large language models (LLMs) have surged in popularity, exemplified by tools like ChatGPT, which showcase versatility across various tasks without the need for additional training.
This raises an intriguing question: Can we develop foundation models for time series data akin to those in natural language processing? Is it feasible for a large model, pre-trained on extensive time series datasets, to deliver precise forecasts on unfamiliar data?
TimeGPT-1, introduced by Azul Garza and Max Mergenthaler-Canseco, incorporates the methodologies and frameworks utilized in LLMs for forecasting applications, successfully establishing the first time series foundation model capable of zero-shot inference.
This article delves into the architecture of TimeGPT, its training process, and its application in a forecasting project to compare its performance with other leading techniques, such as N-BEATS, N-HiTS, and PatchTST.
For in-depth information, please refer to the original paper.

Learn cutting-edge time series analysis strategies with my complimentary time series cheat sheet in Python! Get implementation examples of statistical and deep learning methods, all within Python and TensorFlow!
Let’s dive in!
Exploring TimeGPT
As previously noted, TimeGPT represents a pioneering effort in creating a foundation model tailored for time series forecasting.
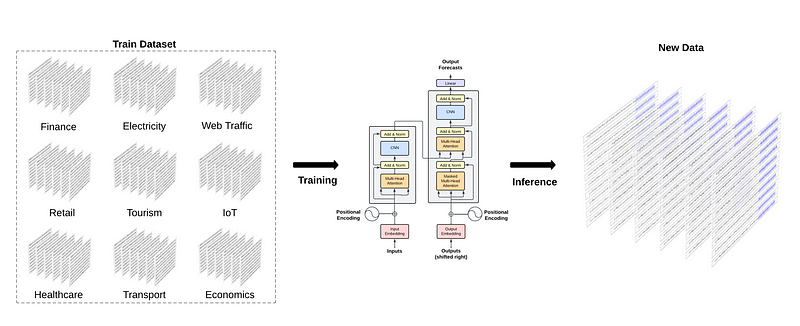
The illustration above demonstrates the core concept behind TimeGPT, which involves training a model on vast datasets from diverse domains to enable zero-shot inference on previously unseen data.
This approach hinges on transfer learning, where a model employs knowledge acquired during its training to tackle new tasks.
However, this effectiveness is contingent upon the model's size and the volume of training data it receives.
Training TimeGPT
To facilitate this, the authors trained TimeGPT using over 100 billion data points sourced from publicly available time series data. This dataset encompasses a broad range of fields, including finance, economics, weather, web traffic, energy, and sales.
The authors have not disclosed the specific public data sources used to compile the 100 billion data points.
This diversity is vital for the foundation model's success, as it allows the model to comprehend various temporal patterns, enhancing its generalization capabilities.
For instance, weather data is expected to exhibit daily (warmer during the day compared to night) and yearly seasonality, while traffic data may demonstrate daily (more vehicles during the day than at night) and weekly seasonality (increased traffic during weekdays compared to weekends).
To ensure the model's robustness and generalizability, preprocessing was minimal. Only missing values were addressed, while the rest of the data remained in its original state. Although the authors did not specify the imputation method used, it is presumed to involve some form of interpolation technique, such as linear, spline, or moving average interpolation.
The model underwent training over several days, during which hyperparameters and learning rates were optimized. While the exact number of days and GPUs used for training is not disclosed, it is known that the model is built on PyTorch and utilizes the Adam optimizer along with a learning rate decay strategy.
The Architecture of TimeGPT
TimeGPT employs the Transformer architecture, featuring a self-attention mechanism, based on the foundational research conducted by Google and the University of Toronto in 2017.
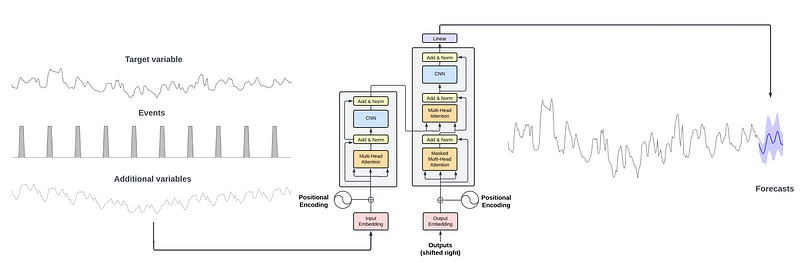
As depicted in the figure, TimeGPT employs a complete encoder-decoder Transformer framework.
The inputs comprise a historical data window, along with exogenous variables such as specific events or additional time series. The encoder processes these inputs, while the attention mechanism learns various features. The decoder then utilizes this learned information to generate forecasts. The prediction sequence continues until it reaches the forecast horizon specified by the user.
Notably, the authors integrated conformal predictions into TimeGPT, enabling the model to estimate prediction intervals based on historical errors.
The Capabilities of TimeGPT
TimeGPT boasts an extensive range of functionalities, especially considering it is a pioneering effort in developing a foundation model for time series forecasting.
Firstly, as a pre-trained model, TimeGPT enables prediction generation without requiring specific training on our dataset. Nonetheless, fine-tuning the model to accommodate our data is also possible.
Secondly, it supports the inclusion of exogenous variables for forecasting and can manage multivariate forecasting tasks.
Lastly, through conformal prediction, TimeGPT can estimate prediction intervals, thus facilitating anomaly detection. Essentially, if a data point falls outside a 99% confidence interval, it is classified as an anomaly.
It's important to note that all these tasks can be accomplished using zero-shot inference or with minimal fine-tuning, marking a significant paradigm shift in the time series forecasting field.
Now that we have a clearer understanding of TimeGPT, its operational mechanics, and training, let’s observe the model in action.
Forecasting with TimeGPT
Let’s implement TimeGPT on a forecasting task and evaluate its performance compared to other models.
At the time of writing this article, TimeGPT is accessible only via API and is currently in closed beta. I submitted a request and received complimentary access to the model for two weeks. To obtain a token and access the model, you must visit their website.
As previously mentioned, the model was trained on 100 billion data points from publicly available data. Since the authors did not specify the actual datasets utilized, testing the model on recognized benchmark datasets, such as ETT or weather, seems impractical, as it likely encountered this data during training.
Consequently, I compiled and open-sourced my dataset for this analysis.
Specifically, I gathered daily views of my blog from January 1, 2020, to October 12, 2023. I also incorporated two exogenous variables: one indicating the publication of a new article and the other flagging holidays in the United States, as most of my audience resides there.
The dataset is now publicly available on GitHub, ensuring that TimeGPT did not train on this data.
As always, you can access the complete notebook on GitHub.
Importing Libraries and Reading the Data
The initial step is to import the necessary libraries for this experiment.
import pandas as pd
import numpy as np
import datetime
import matplotlib.pyplot as plt
from neuralforecast.core import NeuralForecast
from neuralforecast.models import NHITS, NBEATS, PatchTST
from neuralforecast.losses.numpy import mae, mse
from nixtlats import TimeGPT
%matplotlib inline
Next, to access the TimeGPT model, we retrieve the API key from a file. Note that I did not set the API key as an environment variable due to the temporary access.
with open("data/timegpt_api_key.txt", 'r') as file:
API_KEY = file.read()
Subsequently, we can read the dataset.
df = pd.read_csv('data/medium_views_published_holidays.csv')
df['ds'] = pd.to_datetime(df['ds'])
df.head()
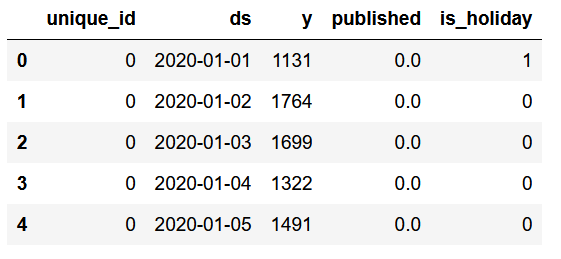
The figure above illustrates that the dataset's format is consistent with other open-source libraries from Nixtla.
We have a unique_id column to differentiate time series, although in this case, there is only one series.
The column 'y' denotes daily blog views, while 'published' serves as a binary indicator for days when new articles were published. Intuitively, we recognize that new content tends to attract more views for a certain duration.
Finally, the 'is_holiday' column signifies whether a holiday occurs in the United States. The rationale is that fewer visitors are likely to access my blog on holidays.
Next, let’s visualize the data to identify patterns.
published_dates = df[df['published'] == 1]
fig, ax = plt.subplots(figsize=(12, 8))
ax.plot(df['ds'], df['y'])
ax.scatter(published_dates['ds'], published_dates['y'], marker='o', color='red', label='New article')
ax.set_xlabel('Day')
ax.set_ylabel('Total views')
ax.legend(loc='best')
fig.autofmt_xdate()
plt.tight_layout()
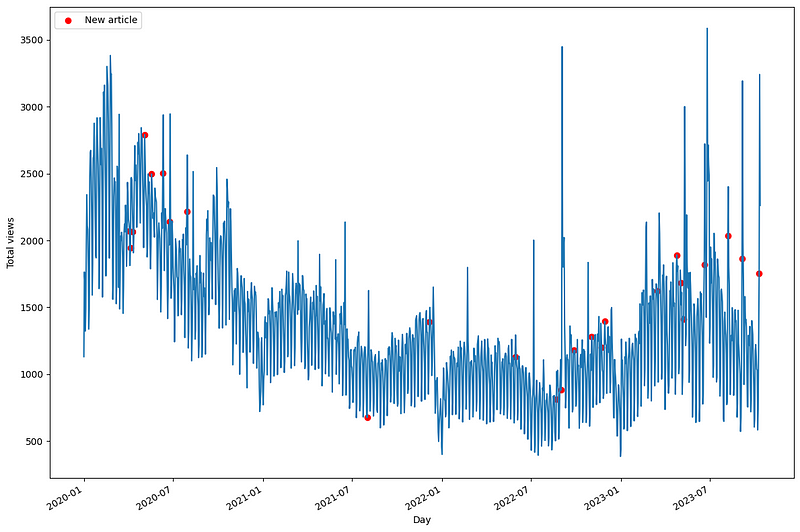
From the figure above, we observe notable trends. The red dots indicate new articles, followed closely by spikes in views.
Additionally, there was reduced activity in 2021, evident in the lower daily views on my blog. In 2023, anomalous spikes in visits were noted following article publications.
A closer examination of the data reveals a clear weekly seasonality.
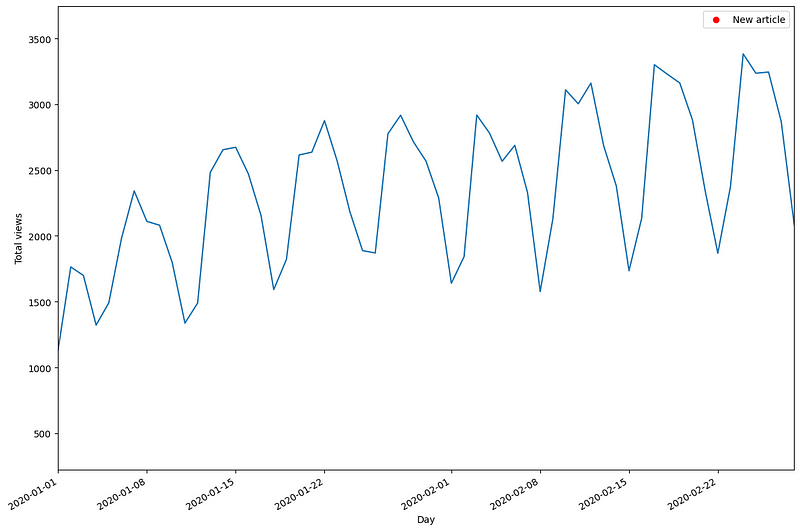
The figure illustrates that fewer visitors frequent the blog during weekends compared to weekdays.
With these insights in mind, let’s explore how to utilize TimeGPT for predictions.
Predicting with TimeGPT
First, we'll divide the dataset into training and testing sets. Here, I'll reserve 168 time steps for the test set, corresponding to 24 weeks of daily data.
train = df[:-168]
test = df[-168:]
Next, we will implement a forecast horizon of seven days, as we aim to predict the daily views for an entire week.
Since the API does not provide a cross-validation implementation, we will create our own loop to generate seven predictions at a time until we cover the entire test set.
future_exog = test[['unique_id', 'ds', 'published', 'is_holiday']]
timegpt = TimeGPT(token=API_KEY)
timegpt_preds = []
for i in range(0, 162, 7):
timegpt_preds_df = timegpt.forecast(
df=df.iloc[:1213 + i],
X_df=future_exog[i:i + 7],
h=7,
finetune_steps=10,
id_col='unique_id',
time_col='ds',
target_col='y'
)
preds = timegpt_preds_df['TimeGPT']
timegpt_preds.extend(preds)
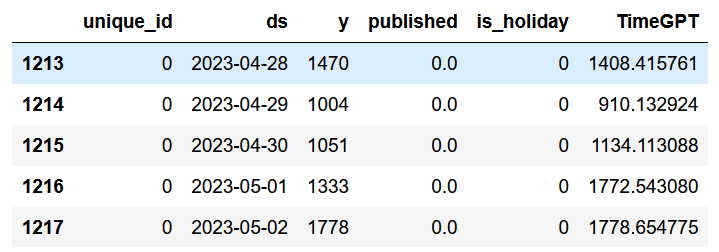
After completing the loop, we can append the predictions to the test set. Since TimeGPT generated seven predictions at a time, we will have 168 predictions available to evaluate its forecasting performance for the following week.
test['TimeGPT'] = timegpt_preds
test.head()
Forecasting with N-BEATS, N-HiTS, and PatchTST
Next, we will apply other models to ascertain whether training them specifically on our dataset yields superior predictions.
For this analysis, we will utilize N-BEATS, N-HiTS, and PatchTST.
horizon = 7
models = [NHITS(h=horizon,
input_size=5*horizon,
max_steps=50),
NBEATS(h=horizon,
input_size=5*horizon,
max_steps=50),
PatchTST(h=horizon,
input_size=5*horizon,
max_steps=50)]
We then initialize the NeuralForecast object and specify the data frequency, which is daily in this context.
nf = NeuralForecast(models=models, freq='D')
Following this, we execute cross-validation across 24 windows of seven time steps to generate predictions aligned with the test set used for TimeGPT.
preds_df = nf.cross_validation(
df=df,
static_df=future_exog,
step_size=7,
n_windows=24
)
Now, we can incorporate the predictions from TimeGPT into the new preds_df DataFrame to consolidate predictions from all models.
preds_df['TimeGPT'] = test['TimeGPT']
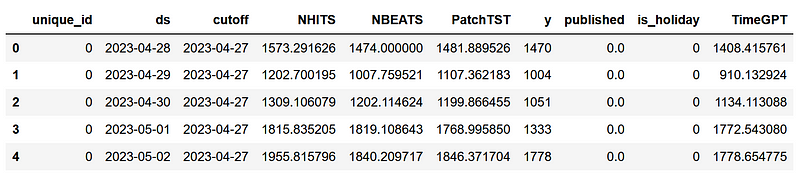
Fantastic! We are now poised to evaluate the performance of each model.
Evaluation
Before analyzing performance metrics, let’s visualize the predictions of each model against our test set.
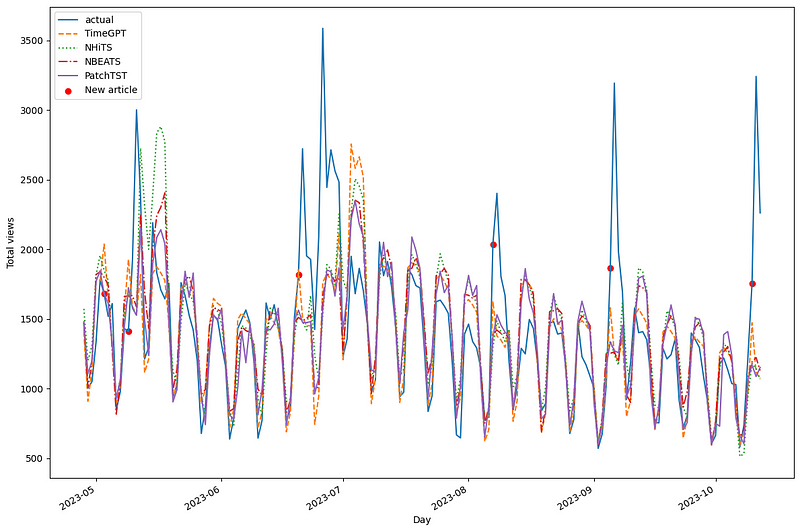
Initially, we notice considerable overlap among the models. However, N-HiTS predicted two peaks not reflected in the actual data. PatchTST frequently undershot predictions, while TimeGPT generally aligns well with the actual data.
To accurately assess each model's performance, we will compute mean absolute error (MAE) and mean squared error (MSE). Predictions will be rounded to whole numbers, as decimals are not meaningful for daily blog visitors.
preds_df = preds_df.round({
'NHITS': 0,
'NBEATS': 0,
'PatchTST': 0,
'TimeGPT': 0
})
data = {
'N-HiTS': [mae(preds_df['NHITS'], preds_df['y']), mse(preds_df['NHITS'], preds_df['y'])],
'N-BEATS': [mae(preds_df['NBEATS'], preds_df['y']), mse(preds_df['NBEATS'], preds_df['y'])],
'PatchTST': [mae(preds_df['PatchTST'], preds_df['y']), mse(preds_df['PatchTST'], preds_df['y'])],
'TimeGPT': [mae(preds_df['TimeGPT'], preds_df['y']), mse(preds_df['TimeGPT'], preds_df['y'])]
}
metrics_df = pd.DataFrame(data=data)
metrics_df.index = ['mae', 'mse']
metrics_df.style.highlight_min(color='lightgreen', axis=1)
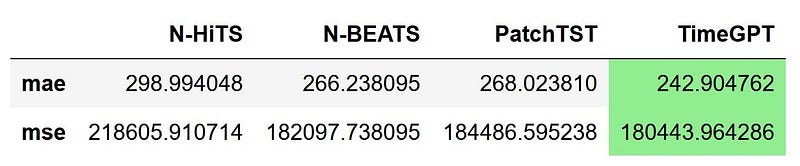
The figure indicates that TimeGPT excels as it achieves the lowest MAE and MSE, followed by N-BEATS, PatchTST, and N-HiTS.
This outcome is promising, considering TimeGPT had not encountered this dataset prior and was only fine-tuned for a limited number of steps. Although this experiment is not exhaustive, it offers a glimpse into the potential of foundational models in forecasting.
My Personal Insights on TimeGPT
While my brief exploration of TimeGPT was exhilarating, I must emphasize that the original paper is somewhat ambiguous in several crucial aspects.
Once again, the specific datasets utilized for training and testing the model remain undisclosed, making it challenging to verify the reported performance metrics.
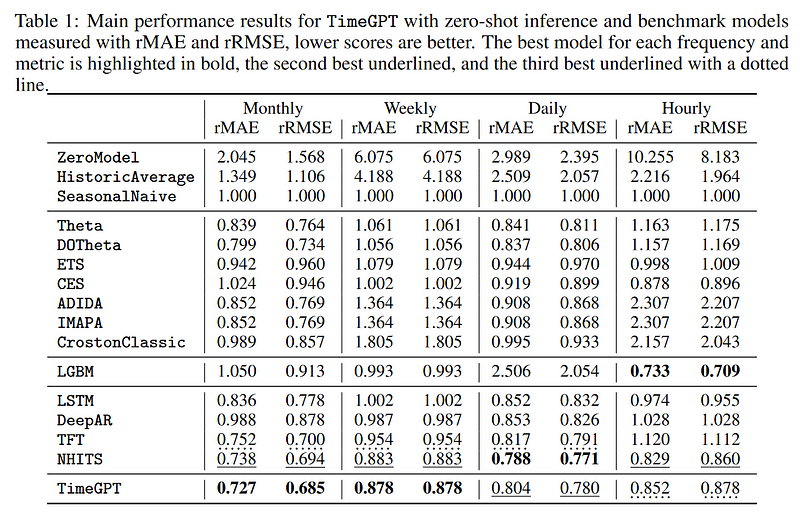
The table shows that TimeGPT performs optimally for monthly and weekly frequencies, with N-HiTS and the Temporal Fusion Transformer (TFT) typically ranking as second or third. However, due to the lack of transparency regarding the data employed, we cannot validate these metrics.
Additionally, there is insufficient clarity surrounding the training process and how the model was tailored for time series data.
It appears that the model is intended for commercial applications, which may explain the absence of reproducibility details in the paper. While this is understandable, the lack of reproducibility is concerning for the scientific community.
Nonetheless, I hope this ignites new research and development in foundational models for time series analysis, ultimately leading to an open-source version of these models, akin to what we observe with LLMs.
Conclusion
TimeGPT marks the introduction of the first foundation model for time series forecasting.
It utilizes the Transformer architecture and has been pre-trained on 100 billion data points, enabling zero-shot inference on new, unseen data.
By incorporating conformal prediction techniques, the model can generate prediction intervals and conduct anomaly detection without being trained on any specific dataset.
I still contend that each forecasting challenge necessitates a tailored approach, so be sure to explore both TimeGPT and other models.
Thank you for your attention! I hope you found this insightful and learned something valuable!
Interested in mastering time series forecasting? Check out my course, Applied Time Series Forecasting in Python. It's the only course that employs Python for implementing statistical, deep learning, and cutting-edge models through 16 guided hands-on projects.
Cheers!
Support My Work
If you enjoy my contributions, consider supporting me through Buy Me a Coffee, a simple way to show your appreciation while I indulge in a cup of coffee! If you feel inclined, just click the button below.

References
TimeGPT-1 by Azul Garza and Max Mergenthaler-Canseco